UVM知识点摘记(Ch2)
UVM知识点摘记(Ch2)
摘记一些UVM知识点,或者自己的理解。备忘,用于查阅。
如:config_db的用法,phase机制的顺序。
系统章节的笔记另开,会有重复。
Ch2 一个简单的UVM验证平台
2.2 只有driver的验证平台
2.2.1 最简单的验证平台
1、UVM是一个库,在这个库中,几乎所有东西都是使用类(class)来实现的。
2、使用UVM的第一条原则是:验证平台中所有的组件应该派生自UVM中的类。
3、所有派生自uvm_driver的类的new函数有两个参数, 一个是string类型的name, 一个是uvm_component类型的parent。
name是这个类的名字,parent在例化时指定,一般是UVM树父节点的名字,通常在父节点中例化,所有parent为this。
在写构造函数时,只写name(在例化时一般指定为drv了),parent设置为null。

4、uvm_info宏,与Verilog中display语句功能类似。验证平台中尽量使用uvm_info取代display。
1 | `uvm_info("my_driver", "data is drived", UVM_LOW) |
第一个参数是字符串,用于打印信息的归类;
第二个参数是字符串,是具体需要打印的信息;
第三个参数是冗余级别,有三个级别:UVM_LOW,UVM_MEDIUM,UVM_HIGH。3.4.1节会讲
述如何显示UVM_HIGH的信息
注意:所有宏不用加分号“;”
打印结果分析:

一共打印出6项:
UVM_INFO:表明这是一个uvm_info宏打印的结果。 除了uvm_info宏外, 还有uvm_error宏、 uvm_warning宏。
my_driver.sv(20):指明此条打印信息的来源, 其中括号里的数字表示原始的uvm_info打印语句在my_driver.sv中的行号。
@51100000:表明此条信息的打印时间。相对于仿真时间。
drv: 这是driver在UVM树中的路径索引(例化时的name)。UVM采用树形结构,对于树中任何一个结点,都有一个与其相应的字符串类型的路径索引。 路径索引可以通过get_full_name函数来获取, 把下列代码加入任何UVM树的结点中就可以得知当前结点的路径索引
[my_driver]:方括号中显示的信息即调用uvm_info宏时传递的第一个参数。
data is drived: 表明宏最终打印的信息。
5、uvm_macros.svh文件通过include语句包含进来。 这是UVM中的一个文件,里面包含了众多的宏定义。
6、import uvm_pkg::*;通过import语句将整个uvm_pkg导入验证平台中。只有导入了这个库,文件时才会认识其中的uvm_driver等类名。
7、xxx_phase中的参数也是phase,这个不需要用户考虑。
2.2.2 加入factory机制
1、UVM的一个特性factory机制,自动创建一个类的实例并调用其中的函数(function)和任务(task) 。
2、factory机制的实现被集成在一个宏中:uvm_component_utils。
这个宏所作的事情可以及学习了解,可以看看UVM这部分的源码。

UVM验证平台的所有类都要factory注册。就是将my_driver这个类登记在UVM内部的一张表上
注册时有两个宏:
uvm_component_utils():派生于uvm_component及其派生类的类使用。(这些类在仿真周期一直存在)
uvm_object_utils():派生于uvm_object的类使用。(这些类有生命周期)
3、run_test(str):可以自动创建一个str实例,自动执行factory注册过的类中的phase。详细的见UVMDemo笔记。
2.2.3 加入objection机制
1、UVM中通过objection(翻译:拒绝,反抗)机制来控制验证平台的关闭。
在每个phase中,UVM会检查是否有objection被提起(raise_objection),如果有,那么等待这个objection被撤销(drop_objection)后停止仿真;如果没有,则马上结束当前phase(就是说没有的话这个phase都不会执行)。
整个验证平台有objection被提起就行,不一定必须在正在执行的phase中。
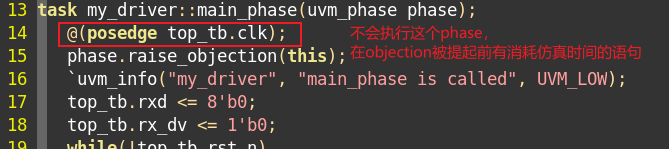
2、objection时进入phase之后才搜索的。如果没有objection被提起,那么不会执行消耗仿真时间的动作,如 @(posedge top_tb.clk); ,但是打印类的不消耗仿真时间的语句还是会被执行的,如uvm_info("my_driver", "enter main_phase", UVM_LOW);。

2.2.4 加入virtual interface
1、关于virtual function。
在验证平台的代码里,phase function都是要用virtual function的。new不需要,自己的function不需要。
原因就是虚方法的原因,多态,多个类都有同名方法。svp226。
==task的话有的有virtual,有的没有,这个再理解一下==
2、加入virtual interface的目的是不使用绝对路径,增加验证平台的可移植性。
从根本上说,应该杜绝在验证平台中使用绝对路径。
3、接口在定义时是interface。在使用时,类中使用虚接口virtual inteface。模块(module中)使用接口interface。

4、config_db机制(用法):详见P85
config_db机制中,分为set和get两步操作。set可以理解为寄信,get理解为收信。常成对出现。
config_db是一个参数化类,这个参数是寄信的类型。如config_db#(int),config_db#(virtual my_if)
set和get是静态函数,所以使用::去调用这个函数。
set用法:
1 | config_db#(type)::set(par1,par2,par3,par4); |
par1(str):第一个参数是uvm_conponent实例的指针,通常是null
par2(str):第二个参数相对于par1实例的相对路径。如:
uvm_test_top.i_agt.drv
par1和par2联合起来组成目标路径(要发给谁),与此路径符合的目标才能收信。
par3(str):第三个参数表示一个记号,说明这个值是传给目标中的哪个成员的。也就是接收方的一个变量名。
par4(val):第四个参数是要设置给变量的值。
这四个参数共同完成一个任务:将一个值par4,传递到par1和par2共同组成的路径下,给到par3变量。
Q:为什么要par1和par2联合组成一个路径,用一个不行吗?
A:可以,但是我理解是,par1给出当前路径,par2给出相对当前路径的相对路径。便于用户指定位置。
get用法:
1 | config_db#(type)::get(par1,par2,par3,par4); |
par1(str):第一个参数是uvm_conponent实例的指针,通常是this。
par2(str):第二个参数相对于par1实例的相对路径。第一个参数设置为this这里就可以为空“”。
par1和par2联合起来组成收信人路径(基本就是当前组件自己),与此路径符合的目标才能收信。
par3(str):set和get的par3必须完全一致,也就是赋值的变量名不能错,否则赋值不上。
par4(name):第四个参数是要设置的变量名。(get的par3和par4一般是同名)
Q:set中par1的设置:(不知理解对否)
A:在top_tb中(一个模块,没有this),用null或者uvm_root::get(),这两个是等价的,是uvm_top。
在其他component中用this就行。
5、build_phase主要完成config_db首发和实例化成员变量等操作。
在build_phase中必须加入super.build_phase语句,因为在其父类中的build_phase中执行了一些必要的操作,这里必须显式的调用并执行他。
super就是父类的指针(this是当前类的指针),这就等于去执行父类中的方法。
关于super:
new方法是必须super显示调用的。查看代码,phase好像都是显式调用了。但是main_phase有的调用有的没有调用,那这个该怎么去决定是否调用呢?
如有变量需要声明,要仿真super前面。(这是规定,也可以理解为super后就开始执行,再声明已经来不及了。)
6、uvm_fatal宏,有两个参数,和uvm_info的前两个参数完全一样。第一个参数是字符串,用于打印信息的归类,第二个参数是字符串,是具体需要打印的信息。
2.3 为验证平台加入各个组件
2.3.1 加入transaction
1、验证平台组件之间信息传递是基于transaction的,transaction就类似一个数据包。
2、post_random()函数是SV中提供,当当前类的实例被随机化函数randomize调用后,post_random()会紧随其后无条件的被调用。
3、在UVM中,所有的transaction都要从uvm_sequence_item派生,只有从uvm_sequence_item派生的transaction才可以使用后文讲述的UVM中强大的sequence机制。有UVM类树上可以看出uvm_sequence_item也是从uvm_transaction中派生出来的。
2.3.2 加入env
1、run_test()只能例化一个组件,验证平台多个组件需要例化。所以构建容器来env,在容器内把所有组件进行例化。这样run_test()传递的参数只要env一个就行了。
2、factory注册后的类,例化不适用new,而是应该使用<type_name>::type_id::create(name,parent)的方式。
1 | drv=my_driver::type_id::create("drv",this); |
第一个参数是name,作为路径的名字。
第二个参数是parent,是该类的父节点的名字,一般在父节点中例化,所以第二个参数一般是this。
config_db中set和get函数中的路径名,都是在例化是指定的name所传递过去的。
2.3.3 加入monitor
1、driver负责把transaction级别的数据转变成DUT的端口级别,并驱动给DUT。monitor的行为与其相对,用于收集DUT的端口数据,并将其转换成transaction交给后续的组件如reference model、 scoreboard等处理。
2.3.4 封装成agent
1、driver和monitor处理同一种协议,代码高度相似,所以可以将二者进行封装。成为一个agent。
2、不同的agent就代表了不同的协议。
3、uvm_agent中的一个成员变量is_active。agent用在DUT的输入和输出,用的driver、sequencer和monitor也是选配的。is_active成员变量就可以用来控制是否例化一些组件。
is_active有两个值UVM_ACTIVE和UVM_PASSIVE。默认值是UVM_ACTIVE,此时例化sqr和drv。UVM_PASSIVE时则只有monitor。
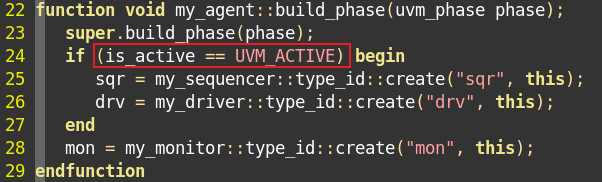
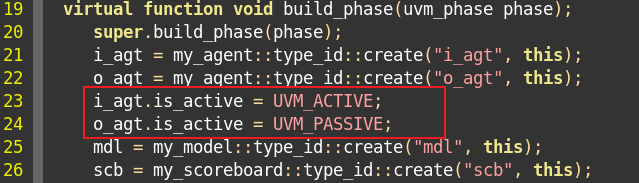
is_active的值是env在例化agent时决定的。
2.3.5 加入reference model
1、reference model和DUT完成一样的功能。(包括不包括时序级别的呢?)
2、在UVM中,通常使用TLM(Transaction Level Modeling)实现component之间transaction级别的通信 。
3、transaction级别的通信中常用数据发送和接收方式:
发送:my_monitor,my_model中使用。
uvm_analysis_port是一个参数化的类,其参数就是这个analysis_port需要传递的数据的类型,在本节中是my_transaction。



在main_phase中,当收集完一个transaction后,需要将其写入ap中,发送transaction。ap.write(tr),write是uvm_analysis_port的一个内建函数。
接收:my_model,my_scoreboard中使用。
uvm_blocking_get_port是一个参数化的类, 其参数是要在blocking_get_port传递的transaction的类型 。



在main_phase中,通过port.get任务来得到从i_agt的monitor中发出的transaction。
4、端口之间的连接。
上述发送接收端口建立好之后,但是模块之间的端口并未连接上。在env中使用fifo来连接各端口。



fifo的类型是uvm_tlm_analysis_fifo,它本身也是一个参数化的类,其参数是存储在其中的transaction的类型。
fifo有两个端口,analysis_export和blocking_get_export端口。分别对应FIFO的读写端口。
通过端口的内建函数connect进行连接,参数是fifo的一个端口,要和自己同名。==(看了ch4回来改正,现在这么想易于理解。)==
Q:为什么用fifo来连接?
A:由于analysis_port是非阻塞性质的,ap.write函数调用完成后马上返回,不会等待数据被接收。假如当write函数调用时,blocking_get_port正在忙于其他事情,而没有准备好接收新的数据时, 此时被write函数写入的my_transaction就需要一个暂存的位置,这就是fifo。 可以理解为解决跨时钟域的问题。
最后将连接关系的理解画成图来看:
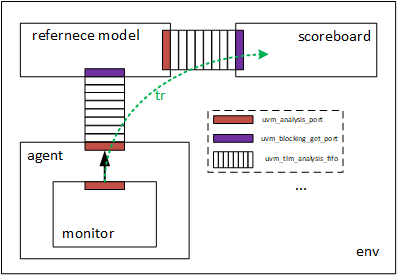
这是对这一节的,还会有oagent到scoreboard的数据流向。
2.3.6 加入scoreboard
1、my_scoreboard要比较的数据一是来源于reference model,二是来源于o_agt的monitor。
2、 scoreboard处理数据方式:在main_phase中通过fork建立起了两个进程,一个进程处理exp_port的数据,当收到数据后, 把数据放入expect_queue中;另外一个进程处理act_port的数据,这是DUT的输出数据,当收集到这些数据后, 从expect_queue中弹出之前从exp_port收到的数据,并调用my_transaction的my_compare函数 。
采用这种比较处理方式的前提是exp_port要比act_port先收到数据。由于DUT处理数据需要延时, 而reference model是基于高级语言的处理,一般不需要延时,因此可以保证exp_port的数据在act_port的数据之前到来。
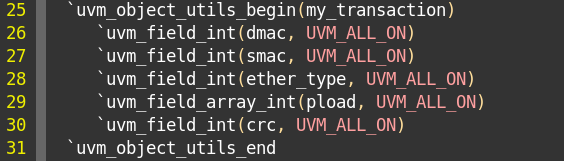
2.3.7 加入field_automation机制
1、field_automation机制,使用uvm_filed系列宏实现。
2、此时factory注册有点变化。原来是uvm_objrct_utils()来注册。

现在变成使用uvm_object_utils_begin和uvm_object_utils_end来实现factory注册。
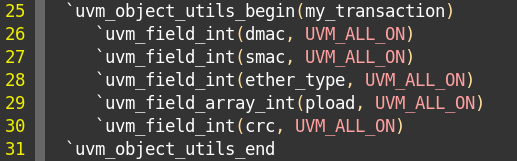
在两个宏中间,使用uvm_field宏注册所有字段。
3、uvm_field系列宏随着transaction成员变量的不同而不同,如上面的定义中出现了针对bit类型的uvm_field_int及针对byte类型动态数组的uvm_field_array_int。 P69
- 最简单的field系列宏
1 |
- 与动态数组有关的
1 |
- 与静态数组有关的
1 |
- 与队列相关的
1 |
- 与联合数组有关的
1 |
具体怎么用,不用记,常用记住就行,其它的用到时进行查阅。
4、使用field_automation机制的好处就是,使用uvm_field宏注册的字段,可以直接调用copy、compare、print等函数。简化了验证平台的搭建。
常用函数有:P71
- copy函数用于实例的复制
如果要把某个A实例复制到B实例中,那么应该使用B.copy(A)。在使用此函数前,B实例必须已经使用new函数分配好了内存空间 。
- compare函数用于比较两个实例是否一样
如果要比较A与B是否一样,可以使用A.compare(B),也可以使用B.compare(A)。当两者一致时,返回1,否则为0。
pack_bytes函数用于将所有的字段打包成byte流
unpack_bytes函数用于将一个byte流逐一恢复到某个类的实例中
pack函数用于将所有的字段打包成bit流
unpack函数用于将一个bit流逐一恢复到某个类的实例中
pack_ints函数用于将所有的字段打包成int(4个byte,或者dword)流,
unpack_ints函数用于将一个int流逐一恢复到某个类的实例中
print函数用于打印所有的字段。
clone函数用于分配一块内存空间, 并把另一个实例复制到这块新的内存空间中
5、把字段放入流中是按照uvm_field宏注册的顺序依次放入的。如下图,就是依次将dmac、smac、ether_type、pload、crc字段,打包成成流。
2.4 UVM的终极大作:sequence
2.4.1 在验证平台中加入sequencer
1、sequence机制用于产生激励。
2、sequence机制有两大部分组成,一是sequence,二是sequencer。
3、uvm_driver也是一个参数化的类,应该在定义driver时指明此driver要驱动的transaction的类型。
这样定义的好处是可以直接使用uvm_driver中的某些预先定义好的成员变量,如uvm_driver中有成员变量req,它的类型就是传递给uvm_driver的参数,在这里就是my_transaction,可以直接使用req。
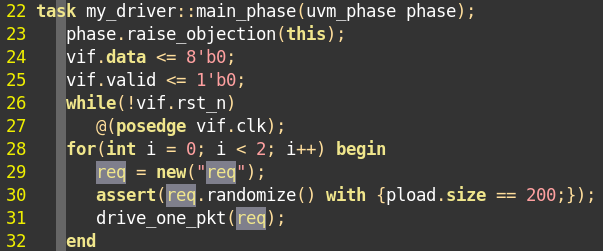
这个req说的不是很清楚,看下uvm源码,这里req是什么作用。好像是个tr。
2.4.2 sequence机制
1、sequence不属于验证平台的任何一部分。(相对于UVM树而言)
2、从本质上说,sequencer是一个uvm_component,sequence是一个uvm_object,派生自uvm_sequence。(从类树上看得出)。
3、sequence是有声明周期的,周期是发送所有transaction的时间。
4、每一个sequence都有一个body任务,当sequence启动后,会自动执行body中的代码。
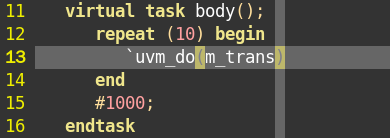
5、sequence中用到了uvm_do宏。uvm_do宏的作用:
1)创建一个my_transaction实例m_trans。
2)将m_trans随机化。
3)将随机化后的m_trans发送给sequencer。
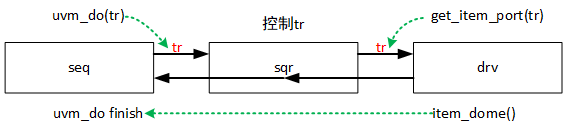
6、sequencer作为中介,对于sequence发送transaction和driver请求transaction的响应。总结下来就是双方都有请求则可以发送,否则需等慢的那个组件发送请求到来,再将transaction从sequence传递到driver。
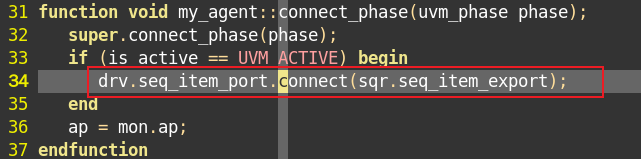
7、向sequencer请求语句:(从命名上感觉是TLM)
driver:uvm_driver中的成员变量seq_item_port
sequence:uvm_sequence中的成员变量seq_item_export
二者之间建立了通道,在my_agent中,使用connect函数把两者联系在一起:
8、driver请求transaction语句:
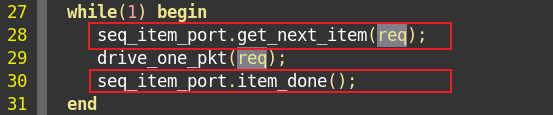
driver使用uvm_driver中的成员变量seq_item_port,通过get_next_item向sequencer申请新的transaction。
driver使用transaction后,通过调用item_done通知sequencer。
这是因为在driver通过get_next_item向sequencer申请transaction后,sequencer发送了tr但是保留tr。若driver返回item_done,则说明发送成功sqr会删除这个tr,否则sqr会再次发送这个tr。(握手机制)
9、sequence发送transaction请求语句:
使用uvm_do宏,uvm_do在driver返回item_done信号后才会返回。
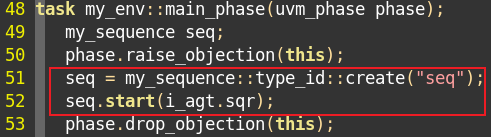
10、某个component(my_sequencer、my_env)的main_phase中启动sequence。例化并启动。
11、在UVM中,objection一般伴随着sequence,通常只在sequence出现的地方才提起和撤销objection。如前面所说,sequence是弹夹,当弹夹里面的子弹用光之后,可以结束仿真了
12、相比于get_next_item,try_next_item的行为更加接近真实driver的行为:当有数据时,就驱动数据,否则总线将一直处于空闲状态 。
2.4.3 default_sequence的使用
1、实际应用中,使用最多的还是通过default_sequence的方式启动sequence。
2、使用default_sequence的方式:在某个component中(如my_env)中设置代码:
1 | uvm_config_db#(uvm_object_wrapper)::set(this, |
参数解释:只有set的前两个参数需要考虑,第三第四以及#()参数都是规定的,按规则写就行。
- par1:当前路径,用this
- par2:相对路径+main_phase。指定phase,使sqr知道在那个phase中启动sequence。
==查阅代码sqr中没有main_phase,这怎么去理解??==
源码中也没说:
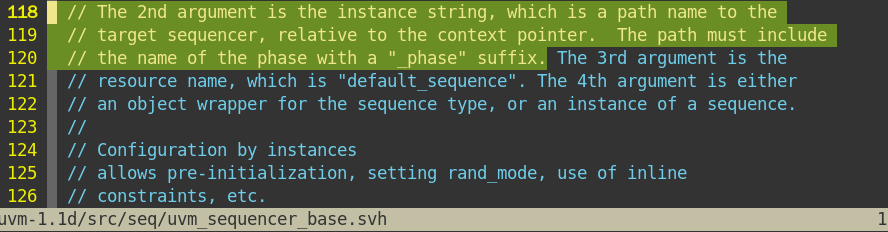
书上P49页。2-72。会自动执行一个main_phase,这个main_phase做了一个starting_phase赋值和启动seq的事情。所以这个main_phase在哪?是不是用户设定的。书上说了自动,应该不用用户操作吧。
找打这个,但不是main_phase。
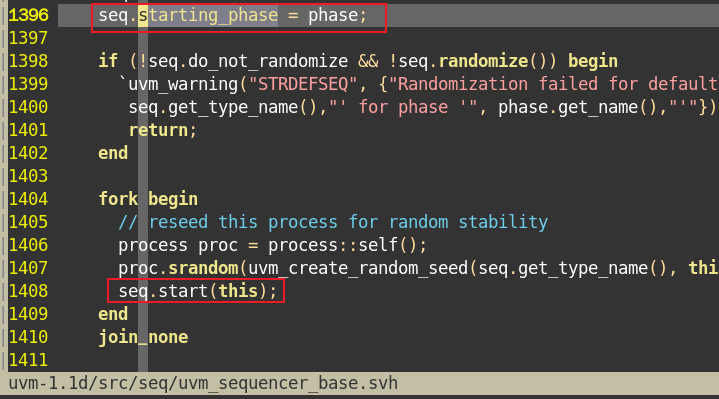
3、不需要get,UVM以及做好。
4、default_sequence下objection机制。
uvm_sequence中有成员变量starting_phase,它的类型是uvm_phase。sequencer在启动default_phase时会自动做如下:
1 | task my_sequencer::main_phase(uvm_phase phase); |
利用starting_phase来执行objection的挂起和撤销。
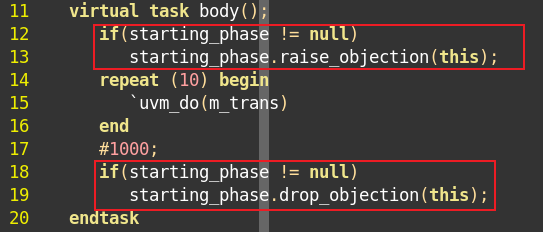
5、在default_sequence中,objection完全与sequence关联在了一起,在其他任何地方都不必再设置objection。
2.5 建造测试用例
2.5.1 加入base_test
1、UVM验证平台中,树根是一个基于uvm_test派生的类。
2、report_phase是UVM内建的一个phase,在main_phase结束之后执行。在report_phase中根据UVM_ERROR的数量来打印不同的信息。
3、base_test中做的一些事情:
1)例化
2)设置验证平台超时时间
3)通过config_db设置一些值。
4)等。
4、第二章平台在新增节点时,每次都需要修改config_db中vif的路径参数,可不可以使用全局变量,方便集中修改。
2.5.2 UVM中测试用例的启动
1、要测试一个DUT是否按照预期工作,需要对其施加不同的激励这些激励被称为测试向量或pattern。 一种激励作为一个测试用例, 不同的激励就是不同的测试用例 。
2、uvm_do_with宏,相比于uvm_do宏,它在随机化时提供对某些字段的约束。

3、通过运行命令执行不同的case,run_test()不设置参数。
1 | # 启动case0 |