UVM知识点摘记(Ch3)
CH3 UVM基础
本章节各节之间没有关联,属于几个知识点的罗列讲解。
3.1 uvm_component与uvm_object
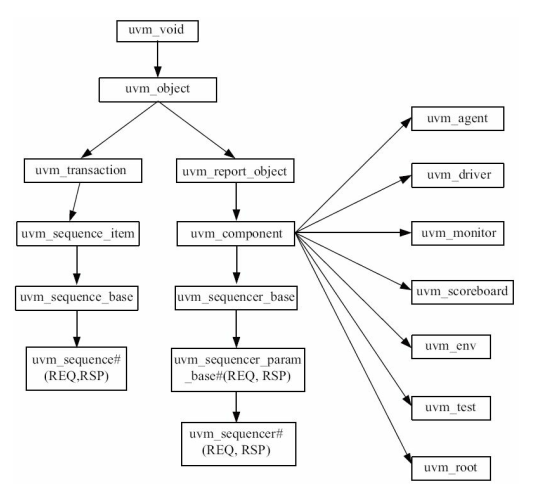
uvm_component和uvm_object是UVM的两个类。如UVM类图所示,uvm_object是由uvm_object所派生出来的,也就是说uvm_object具有比uvm_component更多的特性,属于更详细的类。
比较形象的例子:
uvm_object是一个分子,用这个分子可以搭建成许许多多的东西, 如既可以搭建成动物, 还可以搭建成植物,更加可以搭建成没有任何意识的岩石、空气等。uvm_component就是由其搭建成的一种高级生命, 而sequence_item则是由其搭建成的血液,它流通在各个高级生命(uvm_component)之间,sequence则是众多sequence_item的组合,config则是由其搭建成的用于规范高级生命( uvm_component)行为方式的准则。
需要说明的是,此处
uvm_object指uvm_object本身、及其所派生出来的部分类(UVM类树左侧分支,uvm_transaction等)。
uvm_component指uvm_component类及其派生类。
两个类的特点对比:
| 对比项 | uvm_object | uvm_component |
|---|---|---|
| 例化参数 | name | name、parent |
| UVM树节点 | 不是UVM树节点 | 派生的组件是UVM树节点 |
| phase机制 | 无 | phase机制,自动执行 |
| factory注册方式 | uvm_object_utils() | uvm_component_object() |
| 常用派生类 | uvm_sequence_item、uvm_sequence、config、uvm_reg_item、uvm_phase | uvm_driver、uvm_monitor、uvm_sequencer、uvm_scoreboard、reference model(uvm_componnet)、uvm_agent、uvm_test |
| 内建函数 | clone、copy |
联系:
- uvm_component由uvm_object派生出来。
clone函数语法用于uvm_component的原因是,clone出的新类,其parent参数无法指定。
摘记知识点:
1、uvm_object是UVM中最基本的类。
2、除了派生自uvm_component类之外的类,机会所有的类都派生自uvm_object。
3、DUT是用verilog写成的时序电路,而reference model则可以直接使用SV高级语言的特性,同时还可以通过DPI等接口调用其他语言来完成与DUT相同的功能。
4、所有的测试用例要派生自uvm_test或其派生类。
3.2 UVM的树形结构
uvm_component中的parent参数:
UVM通过uvm_component来实现树形结构,管理验证平台的各个部分。
所有的UVM树的节点本质上都是一个uvm_component。每个uvm_component都有一个特点:它们在new的时候,需要指定一个类型为uvm_component、名字是parent的变量。
1 | function new(string name, uvm_component parent); |
在使用时,parent通常都是this。这是因为compoment都是在他的父节点中被例化,所有,this就是父节点的句柄。
为什么要指定parent?
因为类是由用户实现,用户知道子节点对应关系,而编译器不知道当前类下的子节点有哪些?
父节点这个component的内部有m_children数字,用于记录自己子节点。所以在子节点例化时,指定父节点的名字。就是将子节点的指针加入到父节点的m_children数组中。
这样,父节点根据m_children就知道自己的子节点。字节的通过自己指定的parent知道自己的父节点。
UVM的树根:
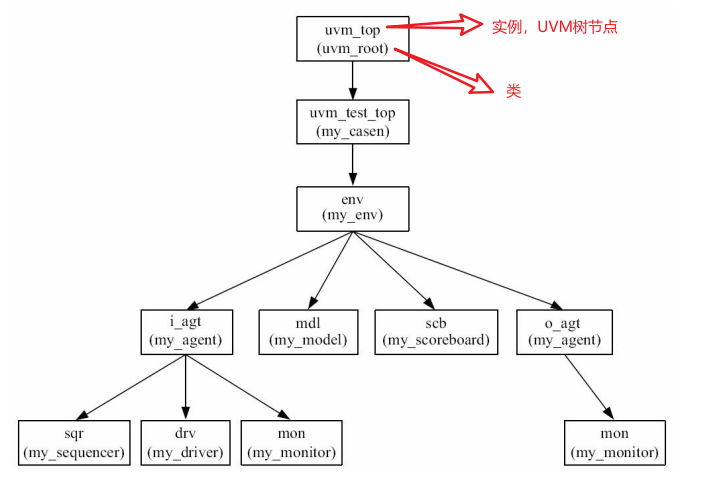
UVM真正的树根是一个称为uvm_top的东西。
uvm_top是一个全局变量,它是uvm_root的一个实例(而且也是唯一一个实例)。
uvm_root派生自uvm_component,所以uvm_top本质上是一个uvm_component,它是树的根。
uvm_test_top的parent是uvm_top,uvm_top的parent是null。
已经有测试用例uvm_test_top,为什么还要uvm_top作为树根?
在UVM中,如果一个component在例化时,其parent被设置为null,那么这个component的parent将会被系统设置为系统中唯一的uvm_root的实例uvm_top。
uvm_root的存在可以保证整个验证平台中只有一棵树,所有节点都是uvm_top的子节点。
uvm_top作为全局变量可以直接使用,如在condif_db中设置路径,第一个参数设置为null,就是uvm_top。或者在第二参数以uvm_top.uvm_test_top索引下去。
也可以通过函数获取:
1 | uvm_root top; |
层次结构的相关函数:
UVM提供了一系列的接口函数用于访问UVM树中的节点。用时查阅即可。
- get_parent():用于得到当前实例的parent。
* get_child(string name):得到当前实例的一个child。
因为父只有一个,所以无需参数指定。而子回应多个,需参数指定得到哪个子的实例。
get_children(ref uvm_component children[$]):得到所有children
get_first_child():获取第一个child
get_next_child():获取下一个child
可以组合使用,获取全部的child:
1 | string name; |
这里name无需赋值,就是这个形式即可。
- get_num_children:返回当前component所拥有child的数量。
3.3 field automation机制
field_automation机制,使用uvm_field系列宏实现。
此时factory注册有点变化。原来是uvm_object_utils()来注册。

现在变成使用uvm_object_utils_begin和uvm_object_utils_end来实现factory注册。
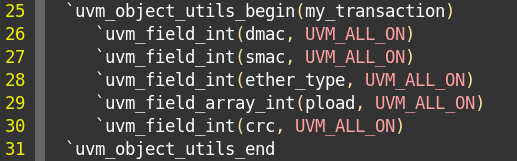
在两个宏中间,使用uvm_field宏注册所有字段。
uvm_field系列宏:
uvm_field系列宏随着transaction成员变量的不同而不同,如上面的定义中出现了针对bit类型的uvm_field_int及针对byte类型动态数组的uvm_field_array_int。
- 最简单的field系列宏
1 |
- 与动态数组有关的
1 |
- 与静态数组有关的
1 |
- 与队列相关的
1 |
- 与联合数组有关的
1 |
具体怎么用,不用记,常用记住就行,其它的用到时进行查阅。
field_automation机制常用函数:
使用field_automation机制的好处就是,使用uvm_field宏注册的字段,可以直接调用copy、compare、print等函数。简化了验证平台的搭建。
常用函数有:
- copy函数用于实例的复制
如果要把某个A实例复制到B实例中,那么应该使用B.copy(A)。在使用此函数前,B实例必须已经使用new函数分配好了内存空间 。
- compare函数用于比较两个实例是否一样
如果要比较A与B是否一样,可以使用A.compare(B),也可以使用B.compare(A)。当两者一致时,返回1,否则为0。
pack_bytes函数用于将所有的字段打包成byte流
unpack_bytes函数用于将一个byte流逐一恢复到某个类的实例中
pack函数用于将所有的字段打包成bit流
unpack函数用于将一个bit流逐一恢复到某个类的实例中
pack_ints函数用于将所有的字段打包成int(4个byte,或者dword)流,
unpack_ints函数用于将一个int流逐一恢复到某个类的实例中
print函数用于打印所有的字段。
clone函数用于分配一块内存空间, 并把另一个实例复制到这块新的内存空间中
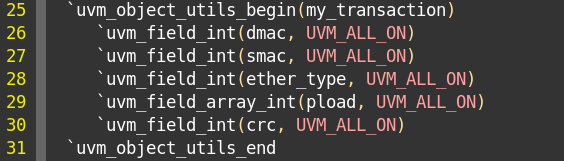
把字段放入流中是按照uvm_field宏注册的顺序依次放入的。如下图,就是依次将dmac、smac、ether_type、pload、crc字段,打包成成流。
field automation机制中标志位的使用:
uvm_field系例宏中基上是两个参数
1 | `uvm_field_int(dmac,UVM_ALL_ON) |
第一个参数就是成员变量。
第二个参数是标记数据,和field_automation机制常用函数控制相关。
为什么要第二个参数作为控制域?
书上的例子,考虑实现这样一种功能:给DUT施加一种CRC错误的异常激励。实现这个功能的一种方法是在my_transaction中添加一个crc_err的标志位。这样,在post_randomize中计算CRC前先检查一下crc_err字段, 如果为1,那么直接使用随机值,否则使用真实的CRC。
只是,对于多出来的这个字段,是不是也应该用uvm_field_int宏来注册呢?如果不使用宏注册的话,那么当调用print函数时,在显示结果中就看不到其值,但是如果使用了宏,结果就是这个根本就不需要在pack和unpack操作中出现的字段出现了。 这会带来极大的问题。UVM考虑到了这一点,它采用在后面的控制域中加入UVM_NOPACK的形式来实现:
对于crc_err的控制域代码:
1 | `uvm_field_int(crc_err, UVM_ALL_ON | UVM_NOPACK) |
以或逻辑符号“|”,组合了UVM_ALL_ON和UVM_NOPACK两个标志位。
这些标志位的核心是17bit的数字。对应上9个函数,和上面的笔记对应。另7bit有其他作用,不讨论。
1 | 来源: UVM |
所以parameter UVM_ALL_ON = 'b000000101010101;对应UVM_COPY、UVM_COMPARE、UVM_PRINT、UVM_RECORD、UVM_PACK开关。与的话就是构造指定开关而已。
宏与if结合:
对于一些字段,在一定情况下才会存在,使用if进行注册和使用。
在my_transaction构造时:
构造所需字段,及其使能标志位。
注册时使用if(is_vlan)的形式控制注册的字段。
1 | class my_transaction extends uvm_sequence_item; |
在随机化时指定is_vlan的值:
1 | my_transaction tr; |
3.4 UVM中打印信息的控制
有点杂乱,用时查阅即可。
打印信息的冗余度
UVM打印是根据冗余度级别来确定的。
UVM会比较要显示信息的冗余度级别与默认冗余度的阈值,如果小于等于阈值,就会显示,否则不会显示。冗余度有三个级别。从高到底依次时:UVM_HIGH、UVM_MEDIUM、UVM_LOW(冗余度高就代表,可以不打印)。默认冗余度阈值时UVM_MEDIUM,所有冗余度低于、等于UVM_MEDIUM的信息都会被打印出来。
- get_report_verbosity_level():等到某个component的冗余度阈值。
返回结果是整数,解释如下:低于、等于说的就是这些整数值。
1 | typedef enum |
- set_report_verbosity_level(Level):设定某个component的冗余度阈值。
若涉及到层次,需要在connect_phase及以后的phase中才能调用这个函数,那就在connect_phase中调用。
- set_report_verbosity_level_hier(Level):递归设置,设置当前component和其子component的冗余度阈值。
uvm_info宏的第一个参数是ID,可以针对ID设置冗余度。
- set_report_id_verbosity():设置当前component的某个ID的冗余度阈值。
- set_report_id_verbosity_hier():递归设置当前component及其子component的某个ID的冗余度阈值。
在命令行中设置冗余度阈值:
1 | <sim command> +UVM_VERBOSITY=UVM_HIGH |
上述的命令行参数会把整个验证平台的冗余度阈值设置为UVM_HIGH。它几乎相当于是在base_test中调用
set_report_verbosity_level_hier函数,把base_test及以下所有component的冗余度级别设置为UVM_HIGH。
那么命令行会覆盖代码中设置的冗余度吗?按道理会。覆盖。
代码中的uvm_info冗余度设置:


1)命令行行中不指定冗余度:
./run_tc my_case0
此时按照代码中设置的冗余度阈值进行打印,base_test中设置冗余度阈值是UVM_HIGH。

执行结果如下,符合预期。

2)覆盖执行冗余度设置:
./run_tc my_case0
此时按照代码中设置的冗余度阈值进行打印,base_test中设置冗余度阈值UVM_LOW覆盖了UVM_HIGH。

执行结果如下,说明会覆盖。
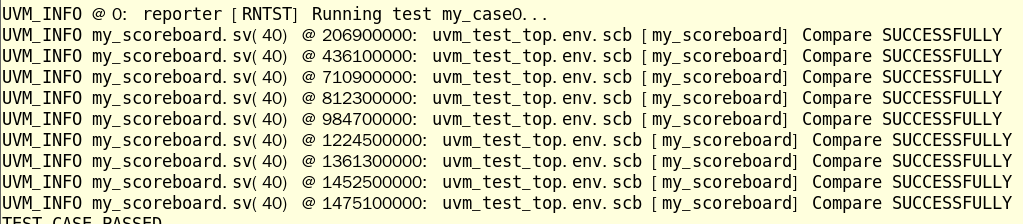
3)命令行中指定冗余度:
./run_tc my_case0 +UVM_VERBOSITY=LOW
此时按照命令行设置的冗余度阈值进行打印,那和base_test中设置冗余度阈值谁的优先级高呢?
结果是没有被覆盖!

==这应该怎么去理解?命令行设置的意义何在?还是我的执行有问题?==
==难受==
书上说:它几乎相当于是在base_test中调用set_report_verbosity_level_hier函数,把base_test及以下所有component的冗余度级别设置为UVM_HIGH。
但是在base_test中set_report_verbosity_level_hier(UVM_LOW)可以达到预期,仿真命令中设置却不可以。
信息打印冗余度设置,这部分就需要有自己的打印设置习惯,便于调试,信息收集。
重载打印信息的严重性
(这部分感觉用的少,应该也就调试时使用,使用时查阅)
UVM默认有四种信息严重性:UVM_INFO、UVM_WARNING、UVM_ERROR、UVM_FATAL。这四种严重性可以相互重载。
与设置冗余度不同,UVM不提供递归的严重性重载函数。严重性重载用的比较少,一般只对某个component内使用。
UVM_ERROR达到一定数量结束仿真
对于某个测试用例,如果出现了大量的UVM_ERROR,根据这些错误已经可以确定bug所在了,再继续仿真下去意义已经不大,此时就可以结束仿真,而不必等到所有的objection被撤销。
set_report_max_quit_count(num):设置最大err退出阈值,满num个err推出仿真。
get_max_quit_count():查询当前退出阈值,0表示不会退出。
在命令行中设置退出阈值:
1 | <sim command> +UVM_MAX_QUIT_COUNT=6,NO |
6:表示UVM_ERROR累计达到6个则退出仿真。
NO:表示不可以被后面设置的语句重载。==怎么理解?==都已经在命令行了,后面怎么会有重载语句。
设置计数的目标
出来设置UVM_ERROR达到一定数量结束仿真,也可以把UVM_WARNING、UVM_INFO、UVM_ERROR计入这个数量。
set_report_severity_action(UVM_WARNING,UVM_DISPLAY|UVM_COUNT):把UVM_WARNING纳入技术范围。
set_report_severity_action_hier():递归
UVM_ERROR已经在计数中,去除计数:
- set_report_severity_action(UVM_ERROR,UVM_DISPLAY):去除UVM_ERROR的计数。
- set_report_id_action(“ID”,UVM_DISPLAY|UVM_COUNT):对特定ID计数,包括INFO,WARNING、ERROR、FATAL。
- set_report_id_action_hier():递归
- set_report_severity_id_action():联合设置。
- set_report_severity_id_action_hier():递归
在命令行中设置计数目标:
1 | <sim command> +uvm_set_action=<comp>,<id>,<severity>,<action> |
UVM的断点功能
在程序调试时,断点功能是非常有用的一个功能。在程序运行时,预先在某语句处设置一断点。当程序执行到此处时,停止仿真,进入交互模式,从而进行调试。
断点功能需要从仿真器的角度进行设置,不同仿真器的设置方式不同。为了消除这些设置方式的不同,UVM支持内建的断点功能,当执行到断点时,自动停止仿真,进入交互模。
主要是UVM_STOP。出现warning,触发断点进入交互模式。
1 | env.i_agt.drv.set_report_severity_action(UVM_WARNING, UVM_DISPLAY| UVM_STOP); |
在命令行设置UVM的断点:
1 | <sim command> +uvm_set_action="uvm_test_top.env.i_agt.drv,my_driver,UVM_WARNING,UVM_DISPLAY|UVM_STOP" |
将输出信息导入文件中
默认情况下,UVM会将UVM_INFO等信息显示在标准输出(终端屏幕)上。
各个仿真器提供将显示在标准输出的信息同时输出到一个日志文件中的功能。但是这个日志文件混杂了所有的UVM_INFO、UVM_WARNING、UVM_ERROR及UVM_FATAL。
UVM提供将特定信息输出到特定日志文件的功能:
1 | info_log = $fopen("info.log", "w"); |
set_report_severity_file():将某种严重性打印信息输出到指定文件中。
set_report_severity_file():递归
同样有ID、ID严重性组合的控制方式:
set_report_id_action
set_report_id_action_hier
set_report_severity_id_file
set_report_severity_id_file_hier
控制打印信息的行为
UVM共定义了如下几种控制打印行为:
1 | typedef enum |
与field automation机制中定义UVM_ALL_ON类似,这里也把UVM_DISPLAY等定义为一个整数。不同的行为有不同的位偏移,所以不同的行为可以使用“或”的方式组合在一起 。
UVM_NO_ACTION是不做任何操作;
UVM_DISPLAY是输出到标准输出上;
UVM_LOG是输出到日志文件中,它能工作的前提是设置好了日志文件;
UVM_COUNT是作为计数目标;
UVM_EXIT是直接退出仿真;
UVM_CALL_HOOK是调用一个回调函数;
UVM_STOP是停止仿真,进入命令行交互模式。
3.5 config_db机制
一个component可以通过get_full_name()函数获得自己的路径。
这里的路径和UVM树的层次是相关的。路径起点是uvm_test_top(原本应该是树根uvm_top,其名字是__top__,在显示路径的时候不显示。),终点是component本身。
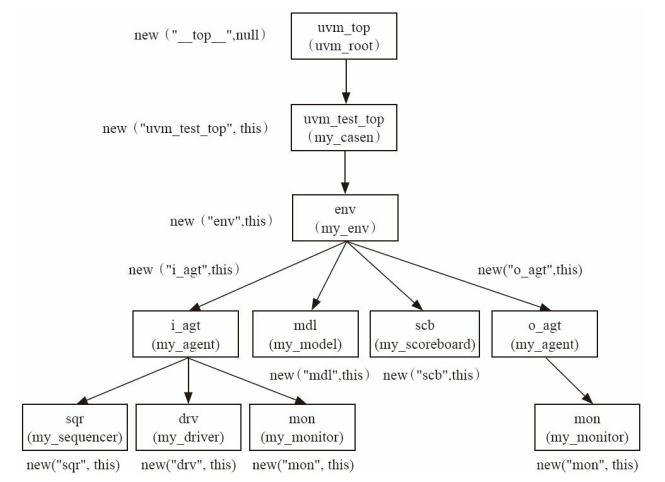
路径与结构层次不一样,但是基本上是一样的。在factory机制例化对象时:
1 | drv = my_driver::type_id::create("driver"); |
drv是例化对象,是层次结构。
“driver”是例化时指定的名字,是路径。
在例化时最好让这两个统一。
config_db机制用于在UVM验证平台间传递参数。包括set寄信,get收信,它们通常是成对出现的。
1)set寄信
一个使用实例如下:
1 | uvm_config_db#(int)::set(this, "env.i_agt.drv", "pre_num", 100); |
#(int)是传递值的类型
其中第一个和第二个参数联合起来组成目标路径,与此路径符合的目标才能收信。
第一个参数必须是一个uvm_component实例的指针,
第二个参数是相对此实例的路径。
第三个参数表示一个记号,用以说明这个值是传给目标中的哪个成员的,
第四个参数是要设置的值。
在module中,第一个参数设置为null,等价于uvm_root::get(),这个值就是uvp_top。
2)get收信
一个使用实例如下:
1 | uvm_config_db#(int)::get(this, "", "pre_num", pre_num); |
get函数中的第一个参数和第二个参数联合起来组成收信人路径。
第一个参数也必须是一个uvm_component实例的指针
第二个参数是相对此实例的路径。一般的,如果第一个参数被设置为this,那么第二个参数可以是空“”。
第三个参数就是set函数中的第三个参数,这两个参数必须严格匹配
第四个参数则是要设置的变量。
set语句没办法省略,在一定条件下,get是被省略的。
在componnet中使用field automation机制,get操作是被省略的。
==也没见set操作啊,只是field注册了一个变量。那再build_phase中省略了get,再build_phase中为什么要get呢?==
set是再case0中set的,书上driver这里是为了说明如何省略get。

这里的关键是build_phase中的super.build_phase语句,当执行到driver的super.build_phase时,会自动执行get语句。
这种做法的前提是:
第一,my_driver必须使用uvm_component_utils宏注册;
第二,pre_num必须使用uvm_field_int宏注册;
第三,在调用set函数的时候,set函数的第三个参数必须与要get函数中变量的名字相一致,即必须是pre_num。
设置多次,获取一次,最终获取到值的问题?
收信时间准则,最近(后)时间收到信具有最优先级。
发信人的权威性准则,层次越高(靠近根节点),优先级越高。
先比较发信人的权威性,再比较收信时间。最终决定哪一封信最终有效。
同一层次的多重设置,以时间准则来确定,实际中使用:
base_test中设置使用最多的值,正常case使用这个值。
非正常测试的case,再次设置新值,按时间准则,就会新值有效。
非直线的set和get。这里的非直线是指,叔侄关系的set和get。这里存在一个问题,之前说过,叔侄关系。同一层次的component是按照字典顺序执行build_phase的,所以无法控制先后设置顺序,可以达到非预期效果。所以不建议非直线的set和get。
config_db对通配符的支持:set操作的第二个参数可以不写完整路径,使用通配符匹配。但是不推荐使用,阅读性差,不利于协作开发。
config_db的调试:
1)check_config_usage:
config_db机制功能非常强大,能够在不同层次对同一参数实现配置。但它的一个致命缺点是,其set函数的第二个参数是字符串,如果字符串写错,那么根本就不能正确地设置参数值。
同时由于第二个参数是字符串,虽然错了,但是也还是一个字符串,所以SystemVerilog的仿真器也不会给出任何参数错误提示。
UVM提供了一个函数check_config_usage,它可以显示出截止到此函数调用时有哪些参数是被设置过但是却没
有被获取过。由于config_db的set及get语句一般都用于build_phase阶段,所以此函数一般在connect_phase被调用。
2)print_config函数:
1 | virtual function void connect_phase(uvm_phase phase); |
其中参数1表示递归的查询,若为0,则只显示当前component的信息。print_config的输出结果中有很多的冗余信息。它会遍历整个验证平台的所有结点,找出哪些被设置过的信息对于它们是可见的。
3)命令行参数UVM_CONFIG_DB_TRACE
1 | <sim command> +UVM_CONFIG_DB_TRACE |