UVM知识点摘记(Ch4)
Ch4 UVM中的TLM1.0通信
TLM1.0
一、现有通信的问题及验证平台内部的通信。
两个component直接如果需要通信的话,有许多方法可以实现。
方法一:全局变量、public变量。这类方法的弊端是单个模块内修改了变量通信就失败了。
方法二:第三方类参与。弊端是第三方类的派生类可能改变变量。
方法三:SV中的mailbox等通信机制。缺点是通信代码建立相对比较麻烦。
通信中还有阻塞、非阻塞的问题。通信是比较复杂的。UVM针对这种问题,使用TLM通信。在component之间建立通道,让信息只能在这个通道内流动,同时赋予阻塞、非阻塞的特性。
二、TLM
TLM(Transaction Level Model)事务级建模。所谓transaction level是相对DUT各个模块之间信号线级别的通信来说的。单来说,一个transaction就是把具有某一特定功能的一组信息封装在一起而成为的一个类。如my_transaction就是把一个MAC帧里的各个字段封装在了一起。
TLM常用术语:
1)put操作:通信的发起者A把一个transaction发送给B。在这个过程中,A称为“发起者”,而B称为“目标”。A具有的端口(用方框表示)称为PORT,而B的端口(用圆圈表示)称为EXPORT。这个过程中,数据流是从A流向B的。
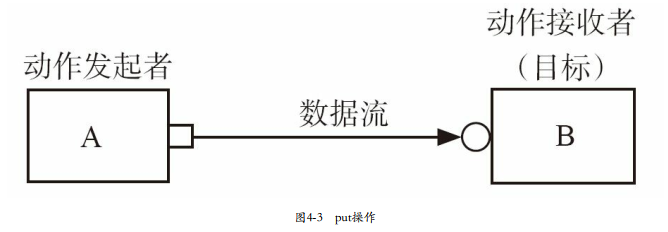
2)get操作:A向B索取一个transaction。在这个过程中,A依然是“发起者”,B依然是“目标”,A上的端口依然是PORT,而B上的端口依然是EXPORT。PORT和EXPORT体现的是控制流而不是数据流。
无论是get还是put操作,其发起者拥有的都是PORT端口。作为一个EXPORT来说,只能被动地接收PORT的命令。

3)transport操作:transport操作相当于一次put操作加一次get操作,这两次操作的“发起者”都是A。在这个过程中,数据流先从A流向B,再从B流向A。在现实世界中,相当于是A向B提交了一个请求(request),而B返回给A一个应答(response)。所以这种transport操作也常常被称做requestresponse操作。
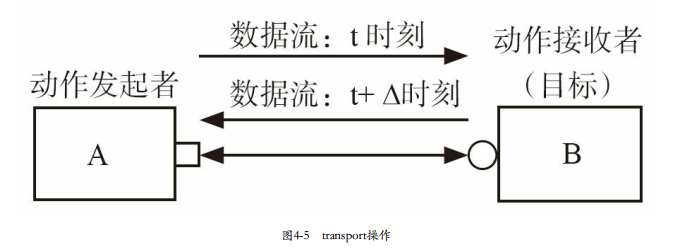
put、get和transport操作都有阻塞和非阻塞之分。
三、PORT和EXPORT
UVM中常用的PORT:
1 | // put系列 |
分组:
按通信动作分为put、get、peek、get_peek、transport;
按端口通信类型分为:blocking(only阻塞型)、nonblocking(only非阻塞型)、none(既可以用于阻塞,也可以用于非阻塞)。
所以在使用前用户一定要想清楚了,这个端口将会用于什么操作。如果想要其执行另外的操作,那么最好的方式是再另外使用一个端口。
参数:
T:PORT中的数据流类型
REQ:发起请求时传输的数据类型
RSP:返回的数据类型
UVM中常用的EXPORT:
1 | uvm_blocking_put_export#(T); |
和PORT一一对应。
PORT和EXPORT体现的是一种控制流,在这种控制流中,PORT具有高优先级,而EXPORT具有低优先级。只有高优先级的端口才能向低优先级的端口发起三种操作。
UVM中各种端口的互联
UVM中TLM通信前要通过端口建立连接关系。
UVM中的端口包括PORT、EXPORT、IMP(implementation port,实现端口)。优先级依次降低。书中使用正方形:white_large_square:,三角形:small_red_triangle:,和圆:white_circle:来表示的。都已blocking_put为例。
1)PORT和EXPORT的连接
UVM中使用connect函数来建立连接关系。如A要和B通信(A是发起者),那么可以这么写:A.port.connect(B.export),但是不能写成B.export.connect(A.port)。因为在通信的过程中,A是发起者,B是被动承担者。这种通信时的主次顺序也适用于连接时,只有发起者才能调用connect函数,而被动承担者则作为connect的参数。
在component中,需要声明,例化端口:
1 | class A extends uvm_component; |
这里端口例化还有指定PORT连接的最大值最小值,默认为1。
在env中建立端口的连接关系:
1 | class my_env extends uvm_env; |

==以上时理想的连接状态,实际使用是不可行的。==
上面连接的逻辑没有任何问题。
但是:反思上述的put操作,A通过其端口A_port把一个transaction传送给B,这个A_port在transaction传输的过程中起了什么作用呢?PORT恰如一道门,EXPORT也如此。既然是一道门,那么它们也就只是一个通行的作用,它不可能把一笔transaction存储下来,因为它只是一道门,没有存储作用,除了转发操作之外不作其他操作。因此,这笔transaction一定要由B_export后续的某个组件进行处理。
所以,在UVM中,完成这种后续处理的也是一种端口:IMP。
IMP:
IMP是UVM中的精髓,承担了UVM中TLM的绝大部分实现代码。
UVM中的IMP:
1 | uvm_blocking_put_imp#(T, IMP); |
这里和上面的PORT和EXPORT完全一样。IMP作为三个端口中优先级最低的,只是通信的被动承担者,这些put等,是响应时使用的。
参数:
T,REQ,RSP和上面一样。
IMP:实现这个接口的一个component。因为IMP最终是调用其所属component的相关任务来处理transaction的。动作执行这最终还是这个component。
所以实际中可以使用的是如下情况:
A中声明端口,并通过这个PORT发送tr:
1 | class A extends uvm_component; |
B中声明PORT和IMP:
1 | class B extends uvm_component; |
env保持不变,只需要连接A的PORT带B的EXPORT上。
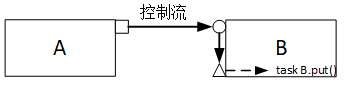
连接结构:A的PORT和B的EXPORT连接。B的EXPORT和B的IMP连接。(还会有隐式的IMP和通过函数/任务关联。)
完整通信过程就是:A的PORT put到B的EXPORT,B的EXPORT又会通知B的IMP。B的IMP就会调用B的同名function/task去处理tranction。
2)PORT和IMP的连接
在1)中PORT是先和EXPORT相连再连接到IMP的。
PORT可以和IMP直接相连。
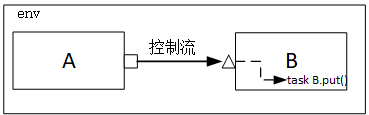
IMP的new函数与PORT的相似,第一个参数是名字,第二个参数是一个uvm_component的变量,一般填写this即可。
关于IMP对应的function/task的名字的问题:
B中的关键是定义一个任务/函数put。回顾一下,上节中在介绍IMP的时候,A_port的put操作最终要落到B的put上。所以在B中要定义一个名字为put的任务/函数。这里有如下的规律:
当A_port的类型是nonblocking_put(为了方便,省略了前缀uvm_和后缀_port,下同),B_imp的类型是nonblocking_put(为了方便,省略了前缀uvm_和后缀_imp,下同)时,那么就要在B中定义一个名字为try_put的函数和一个名为can_put的函数。
当A_port的类型是put,B_imp的类型是put时,那么就要在B中定义3个接口,一个是put任务/函数,一个是try_put函数,一个是can_put函数。
当A_port的类型是blocking_get,B_imp的类型是blocking_get时,那么就要在B中定义一个名字为get的任务/函数。
当A_port的类型是nonblocking_get,B_imp的类型是nonblocking_get时,那么就要在B中定义一个名字为try_get的函数和一个名为can_get的函数。
当A_port的类型是get,B_imp的类型是get时,那么就要在B中定义3个接口,一个是get任务/函数,一个是try_get函数,一个是can_get函数。
当A_port的类型是blocking_peek,B_imp的类型是blocking_peek时,那么就要在B中定义一个名字为peek的任务/函数。
当A_port的类型是nonblocking_peek,B_imp的类型是nonblocking_peek时,那么就要在B中定义一个名字为try_peek的函数和一个名为can_peek的函数。
当A_port的类型是peek,B_imp的类型是peek时,那么就要在B中定义3个接口,一个是peek任务/函数,一个是try_peek函数,一个是can_peek函数。
当A_port的类型是blocking_get_peek,B_imp的类型是blocking_get_peek时,那么就要在B中定义一个名字为get的任务/函数,一个名字为peek的任务/函数。
当A_port的类型是nonblocking_get_peek,B_imp的类型是nonblocking_get_peek时,那么就要在B中定义一个名字为try_get的函数,一个名为can_get的函数,一个名字为try_peek的函数和一个名为can_peek的函数。
当A_port的类型是get_peek,B_imp的类型是get_peek时,那么就要在B中定义6个接口,一个是get任务/函数,一个是try_get函数,一个是can_get函数,一个是peek任务/函数,一个是try_peek函数,一个是can_peek函数。
当A_port的类型是blocking_transport,B_imp的类型是blocking_transport时,那么就要在B中定义一个名字为transport的任务/函数。
当A_port的类型是nonblocking_transport,B_imp的类型是nonblocking_transport时,那么就要在B中定义一个名字为nb_transport的函数。
当A_port的类型是transport,B_imp的类型是transport时,那么就要在B中定义两个接口,一个是transport任务/函数,一个是nb_transport函数。
在前述的这些规律中,对于所有blocking系列的端口来说,可以定义相应的任务或函数,如对于blocking_put端口来说,可以定义名字为put的任务,也可以定义名字为put的函数。这是因为A会调用B中名字为put的接口,而不管这个接口的类型。由于A中的put是个任务,所以B中的put可以是任务,也可以是函数。但是对于nonblocking系列端口来说,只能定义函数。
总结下:
1、A_port是什么类型,B_imp就必须是什么类型。如A_port的类型是blocking_transport,那么B_imp的类型必须是是blocking_transport。
2、需要定义的函数/接口名 | 函数还任务
- blocking系列的端口:(函数/任务)
- get/put/peek/transport:一个名为get/put/peek/transport的任务/函数。
- get_peek:一个名字为get的任务/函数,一个名字为peek的任务/函数。
- nonblocking系列端口:(函数)
- get/put/peek:一个名字为try_get/put/peek的函数,一个名为can_get/put/peek的函数。
- get_peek:一个名字为try_get的函数,一个名为can_get的函数,一个名字为try_peek的函数和一个名为can_peek的函数。
- transport:一个名字为nb_transport的函数
- none系列端口:(比nonblocking多一个)
- get/put/peek:一个是get/put/peek任务/函数,一个名字为try_get/put/peek的函数,一个名为can_get/put/peek的函数。
- get_peek:一个是get任务/函数,一个名字为try_get的函数,一个名为can_get的函数;一个是peek任务/函数,一个名字为try_peek的函数和一个名为can_peek的函数。
- transport:一个是transport任务/函数,一个名字为nb_transport的函数。
3)EXPORT和IMP的连接
和前面一样的逻辑,定义端口,在env中连接即可。
1 | A_inst.A_export.connect(B_inst.B_imp); |
4)PORT与PORT的连接
这是属于同类型,同优先级端口之间的连接。
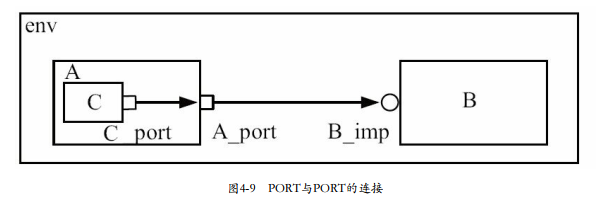
也比较常规,在A中例化C,把C的port连接到A的port上就可以。(C是发起方。)
5)EXPORT和EXPORT的连接
基本同上
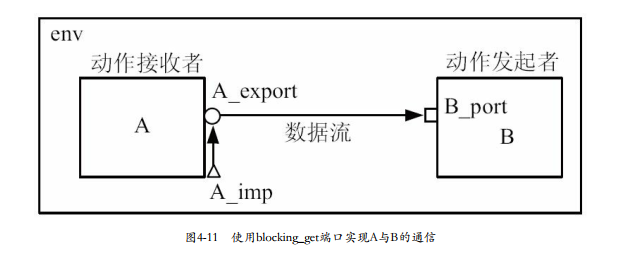
blocking_get端口的使用:
PORT作为发起方,执行blocking_get动作。控制流由B到A,而数据流是A到B。
blocking_transport端口的使用:
transport通信是双向的。
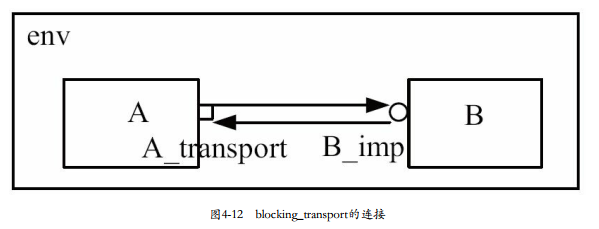
PORT作为发起方,A:
1 | class A extends uvm_component; |
A_transport.transport(tr, rsp);一方面是把tr发送到imp,另一方面是收到imp发送回来的rsp。
B作为IMP:
1 | class B extends uvm_component; |
my_transaction req 是收到的tr,output my_transaction rsp发送回去的tr。
env中连接:
1 | function void my_env::connect_phase(uvm_phase phase); |
在A中调用transport任务,并把生成的transaction作为第一个参数。B中的transaport任务接收到这笔transaction,根据这笔transaction做某些操作,并把操作的结果作为transport的第二个参数发送出去。A根据接收到的rsp来决定后面的行为。
在本例中,是blocking_transport_port直接连接到blocking_transport_imp,前者还可以连接到blocking_transport_export,这三者之间的连接关系与blocking_put系列端口类似。
nonblocking端口的使用:
nonblocking端口的所以操作都是非阻塞的,必须用函数实现,而不能用任务实现。
因为是非阻塞的,put后会立即返回,所以既然要put就要保证可以put。所以会用can_put函数来确认是否能够执行put操作。can_put函数要在动作接收方里实现。
UVM中的通信方式
一、UVM中的analysis端口
UVM中除了PORT、EXPORT、IMP还有两个特殊的端口:analysis_port和analysis_export。这两者与put、get系列端口类似,都用于传递transaction。
区别:
第一,默认情况下,一个analysis_port(analysis_export)可以连接多个IMP,也就是说,analysis_port(analysis_export)与IMP之间的通信是一对多的通信,而put和get系列端口与相应IMP的通信是一对一的通信(除非在实例化时指定可以连接的数量,参照4.2.1节A_port的new函数原型代码清单4-4)。analysis_port(analysis_export)更像是一个广播。
第二,put与get系列端口都有阻塞和非阻塞的区分。但是对于analysis_port和analysis_export来说,没有阻塞和非阻塞的概念。因为它本身就是广播,不必等待与其相连的其他端口的响应,所以不存在阻塞和非阻塞。
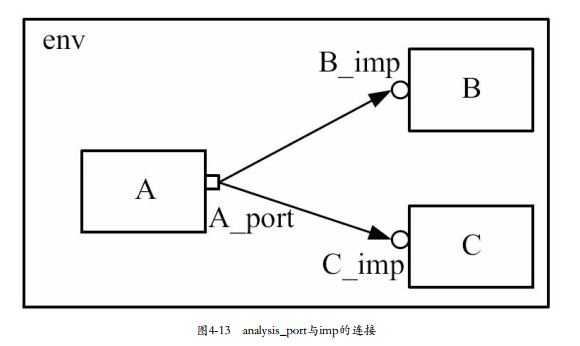
一个analysis_port可以和多个IMP相连接进行通信,但是IMP的类型必须是uvm_analysis_imp,否则会报错。
对于put系列端口,有put、try_put、can_put等操作,对于get系列端口,有get、try_get和can_get等操作。对于analysis_port和analysis_export来说,只有一种操作:write(因为是广播)。在analysis_imp所在的component,必须定义一个名字为write的函数。
图中的连接关系,
A:定义、例化analysis_port,写transaction(write)
1 | class A extends uvm_component; |
B、C:声明、例化analysis_imp,需要实现write函数,imp收到tr后执行该函数。
1 | class B extends uvm_component; |
env:设置连接。
1 | function void my_env::connect_phase(uvm_phase phase); |
二、一个component内有多个IMP
一个component内有多个IMP,那就要对应对各write函数来处理transacion。
UVM中使用宏uvm_analysis_imp_decl来处理。
1 | // 宏声明 |
上述代码通过宏uvm_analysis_imp_decl声明了两个后缀\_monitor和\_model。UVM会根据这两个后缀定义两个新的IMP类:uvm_analysis_imp_monitor和uvm_analysis_imp_model,并在my_scoreboard中分别实例化这两个类:monitor_imp和model_imp。当与monitor_imp相连接的analysis_port执行write函数时,会自动调用write_monitor函数,而与model_imp相连接的analysis_port执行write函数时,会自动调用write_model函数。所以,只要完成后缀的声明,并在write后面添加上相应的后缀就可以正常工作了:
三、使用FIFO通信
使用的是uvm_analysis_fifo。FIFO本质是一块缓存加两个IMP(端口连接中必须要有),所以FIFO的两个端口都是IMP的d。
env中的连接关系:
1 | class my_env extends uvm_env; |
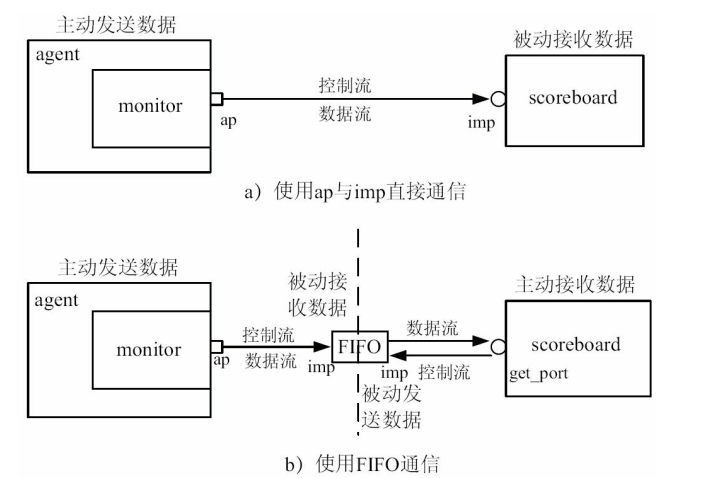
连接关系如图所示。
虽然FIFO的端口名是EXPORT,但是本质上是IMP。
如何收发数据的?
monitor的端口是ap端口,monitor是数据发送方。二者通信的控制流和数据流都是从monitor到FIFO。
scb的端口是get_port,scb是数据的接受方。控制流从scb到FIFO,数据流从FIFO到scb。
IMP是如何实现的?
本质上就是一个FIFO读写的过程,ap端口发送数据时,FIFO作为IMP没有调用component的task,二是fifo本身的缓存存储了数据。同样,get_port端口读取数据,FIFO作为IMP只是将缓存的数据发送出去。component的write在write中实现了。
四、FIFO上的端口及调试
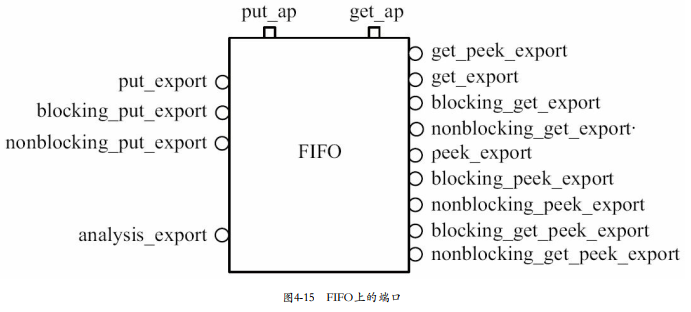
uvm_analysis_fifo的端口有很多,这里有两个port口:put_ap和get_ap,
有点疑问,它们最终接到了哪里?终点应该是IMP才对。
FIFO中的常用函数:
used:查询FIFO中有多少transaction。FIFO例化时的第三个参数时size上限,默认值是1。
flush:清空FIFO中所有数据,常在复位时使用。